Before the integration between Synapse and AML (Azure Machine Learning) was possible, when you wanted to bring Azure Machine Learning capability into your data platform, you would store your data in the data lake, set the lake up as a datastore in AML, do all the training and scoring of machine learning models in AML, push the scoring back to the lake, then serve the result directly in Power BI or via a serving layer like Synapse.
With the development of Synapse’s integration features with AML, there are a lot more possibilities today to bring data science capabilities into Synapse. In this blog, I summarize five ways you can integrate these two core Azure Data Services.
1.PREDICT in Dedicated SQL Pool
PREDICT in Synapse Dedicated SQL Pool is in engine SQL scoring. You can use this functionality to score the data stored in Synapse Dedicated SQL Pool with no data leaving the Dedicated SQL Pool. Instead, the trained model is brought into Dedicated SQL Pool and Stored in a table and a stored procedure is created score the data against the imported model using the Synapse UI.
It is important to note that with this functionality, training of Machine Learning model is not done by Dedicated SQL Pool. This functionality can only predict ONNX models registered in AML, you can train an ONNX model using AML, or use Synapse Spark Pool to trigger an AutoML run in AML with ONNX enabled. Because ONNX is open standard, you can also use other tools to train an ONNX model and register it with AML.
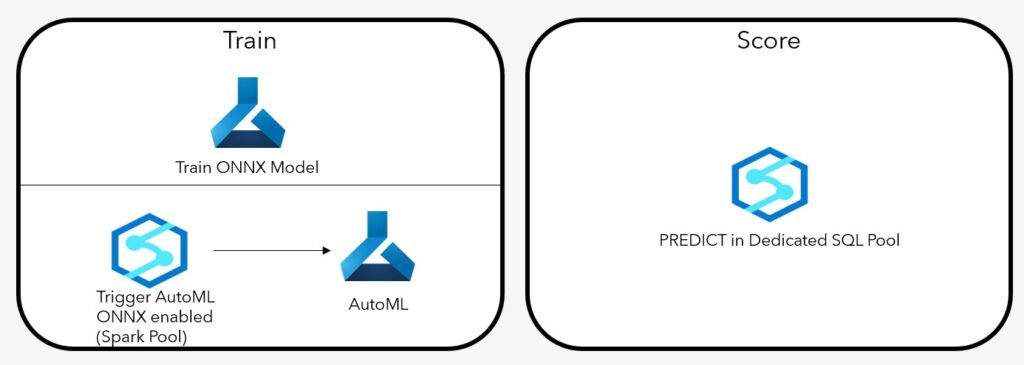
Follow this tutorial for using PREDICT in Dedicated SQL Pool.
2. PREDICT in Synapse Spark Pool
Unlike PREDICT in Dedicated SQL Pool, PREDICT in Synapse Spark Pool works with MLFLOW Packaged Model. At the time of writing this blog, machine learning models packages in MLflow format such as TensorFlow, ONNX, PyTorch, SkLearn and pyfunc are supported.
Also different from PREDICT in Dedicated SQL Pool, both training and scoring of the machine learning model can be done using Synapse Spark Pool. Alternatively, training of MLFLOW packaged model can be done in AML with scoring done in Synapse Spark Pool using PREDICT.
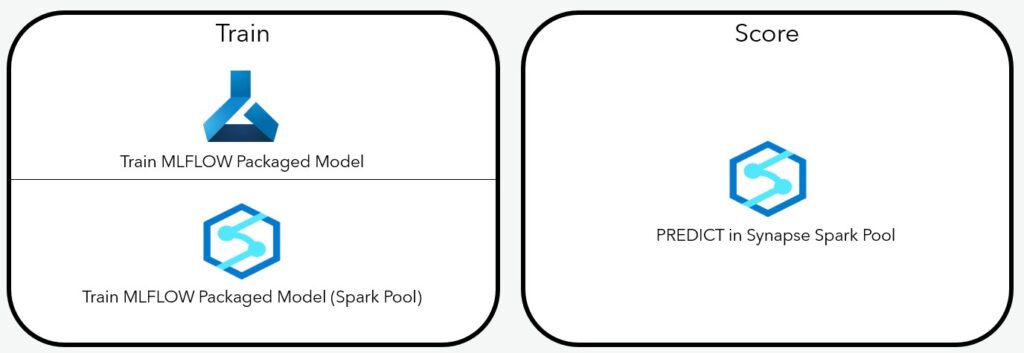
Follow this hands-on lab for using PREDICT in Synapse Spark Pool.
3. Use Synapse Spark in AML
With compute instance, compute cluster, Kubernetes and more, you have a lot of choices of compute target in Azure Machine Learning. But Spark is not a native type of compute you can create within AML. In order to use Spark in Azure Machine Learning, you will need to attach your own compute using either Databricks or Synapse Spark Pool. You can use Synapse Spark Pool in a Azure Machine Learning Pipeline or in an interactive session.
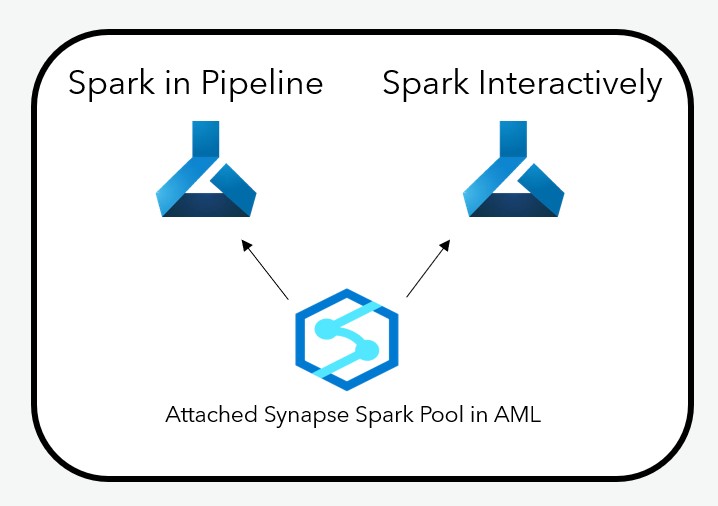
Follow this hands-on Lab for using Synapse Spark in AML both in an AML Pipeline and in an interactive session.
4. Orchestrate AML Batch Inference Service in Synapse
With data integration pipelines in Synapse, you can orchestrate the cleansing/transformation of retraining/scoring data with the running of the AML retraining/scoring pipeline. The retraining/scoring pipelines are typically run at different frequency. With data integration pipeline triggers, you can run them with a schedule or on an event trigger (based on new files landing in the lake).
The cleansing/transformation of retraining/scoring data can be done using mapping data flows in a code free manner or using spark notebooks in a code first manner.
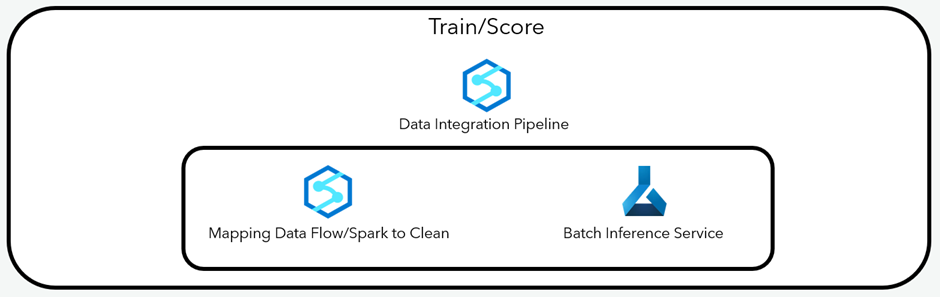
Follow this lands-on lab for Orchestrate AML Batch Inference Service in Synapse
5. Structured Streaming + Real Time Inferencing
All above mentioned integration use cases are good for batch process. What if you have streaming data that needs to be scored? You can use the structured streaming capability in Synapse Spark Pool to stream data in, do the transformation you need with the streaming dataframe, create a pandas UDF in which you would select the features you need and call the AML Real Time inference service Rest endpoint, then create a foreachbatch to use the pandas UDF, which will create a mini batch Spark Dataframe and score against the AML Model deployed on Real Time inference for which mini batch.
Example code below
realtimedf.writeStream.foreachBatch(“<pandasudfName>”).outputMode(“append”).option(“checkpointLocation”, “<checkpointLocation>”).start()
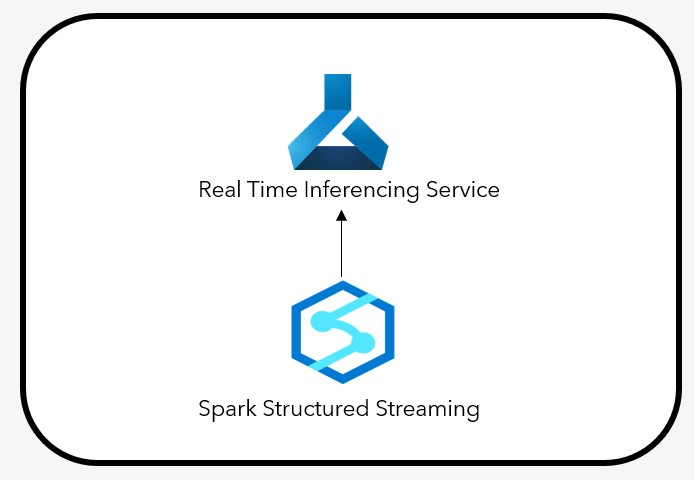
You can see here for examples for the pandas UDF.
Additional AI Capabilities in Synapse
In addition to integration with Azure Machine Learning, Synapse has some other Machine Learning and AI capabilities. For example, you can use Synapse Spark Pool to train a Spark MLLib model. With Azure Data Explorer brought into Synapse, you can also utilize the AI capabilities in Kusto pool, such as Time series analysis, Anomaly detection and forecasting, and Machine learning Clustering. Moreover, you can use the Synapse integration with Cognitive Services to make use of machine learning models trained by Microsoft.