Those of you who have adopted Unity Catalog in Databricks and are using Azure Data Factory(ADF) in conjunction might have noticed that ADF’s delta lake connector has not been fully updated for Unity Catalog tables yet. You can only select database name and table name when creating a dataset using the connector, which means the three-level namespace Unity Catalog tables are not accessible using this route.
While I know ADF product team is working hard to get this updated, this blog outlines two workarounds.
Option 1. Use Query with Delta Lake Connector
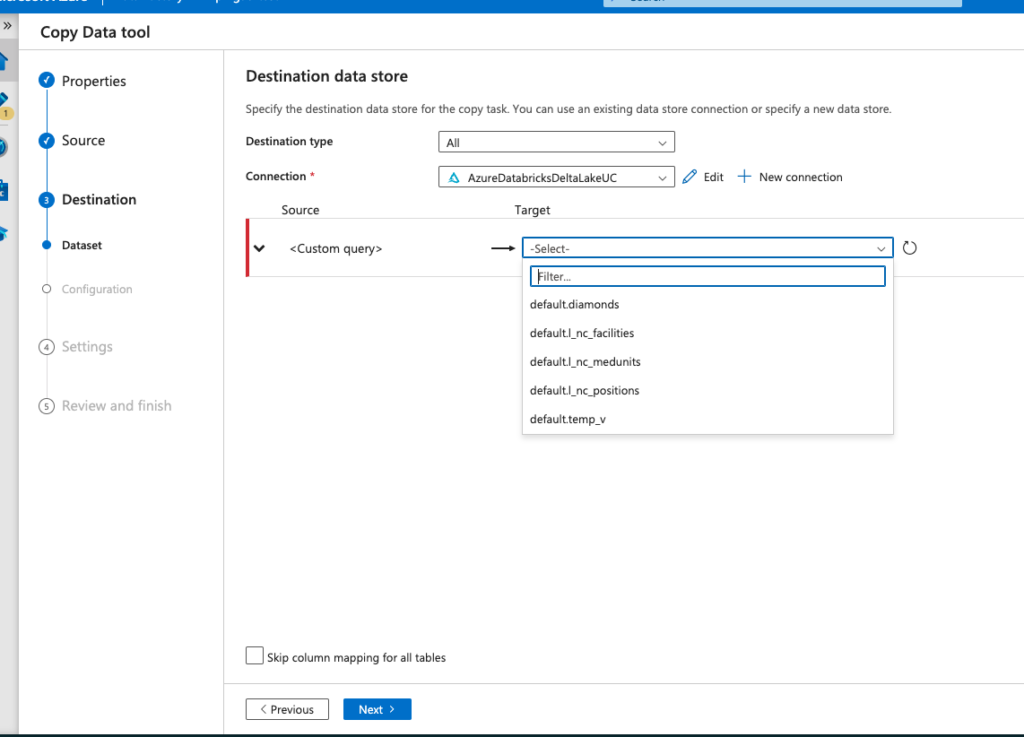
When using Copy Data Tool during source configuration, existing tables will only give you all the tables in hive_metastore (the tables that are not governed by Unity Catalog).
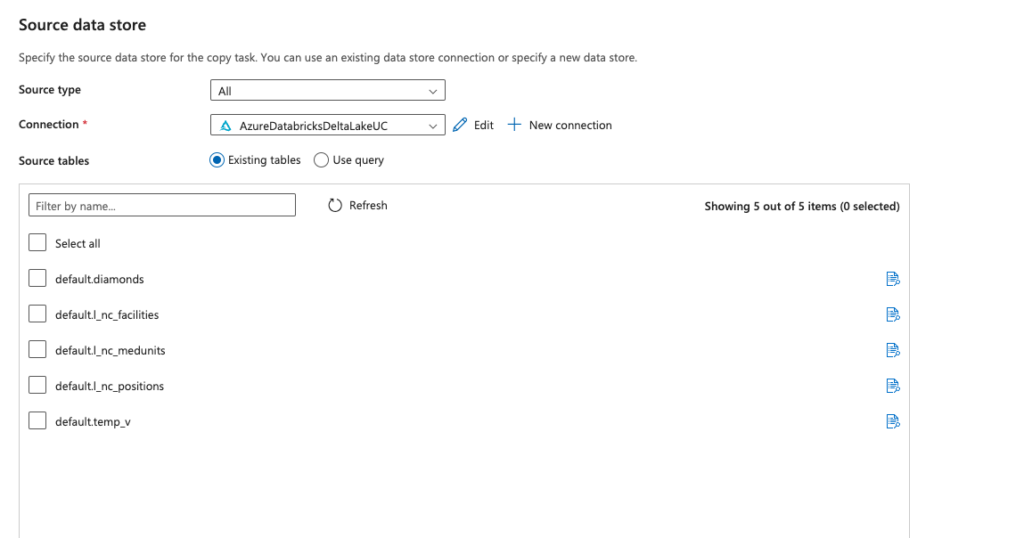
However, by using Use Query, you can do a select statement using a three-level namespace, (“select * from catalog.database.table”)
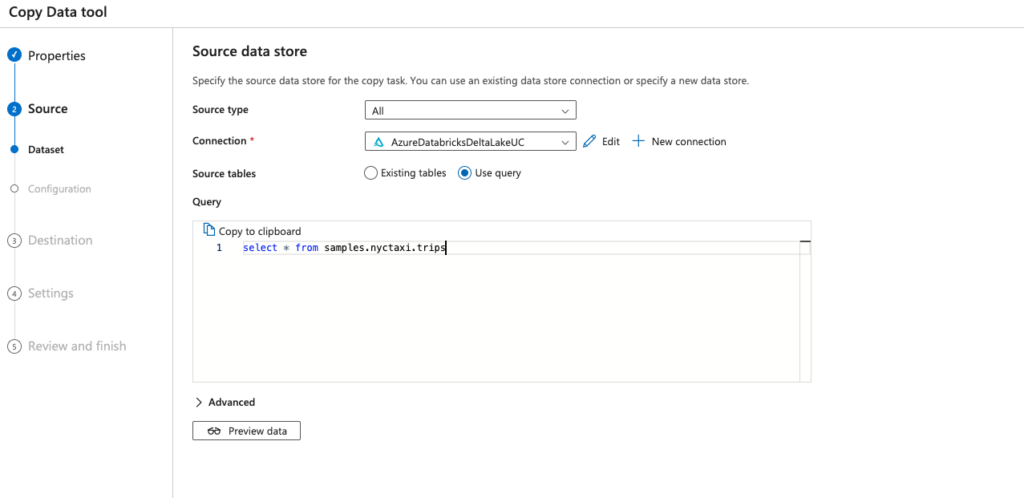
Note: This option only works for copy from. As destination data store can only be selected from hive_metastore tables and not three-level namespace tables.
Option 2. Use ODBC connector
- Provision a VM in a subnet in the same Vnet where Databricks sits, alternatively you can set up a VM in a subnet in a different Vnet that is peered with the Databricks Vnet
- Create ADF Self Hosted Integration Runtime (SHIR) and install the SHIR on the VM provisioned in step 1 Microsoft Doc
- Install ODBC Driver on the same VM documentation for JDBC/ODBC configuration
- Set user DSN/system DSN
- Create a ADF ODBC Linked Service using SHIR, connection string below. In Addition to Connection String, you will need to set username and password, password is PAT you get from Databricks.
DSN=<the DSN name you set>;Driver=C:\Program Files\Simba Spark ODBC Driver;Host=<get from the SQL warehouse in databricks>;Port=443;HTTPPath=<Get from the SQL warehouse in Databricks>;ThriftTransport=2;SSL=1;AuthMech=3;UID=token
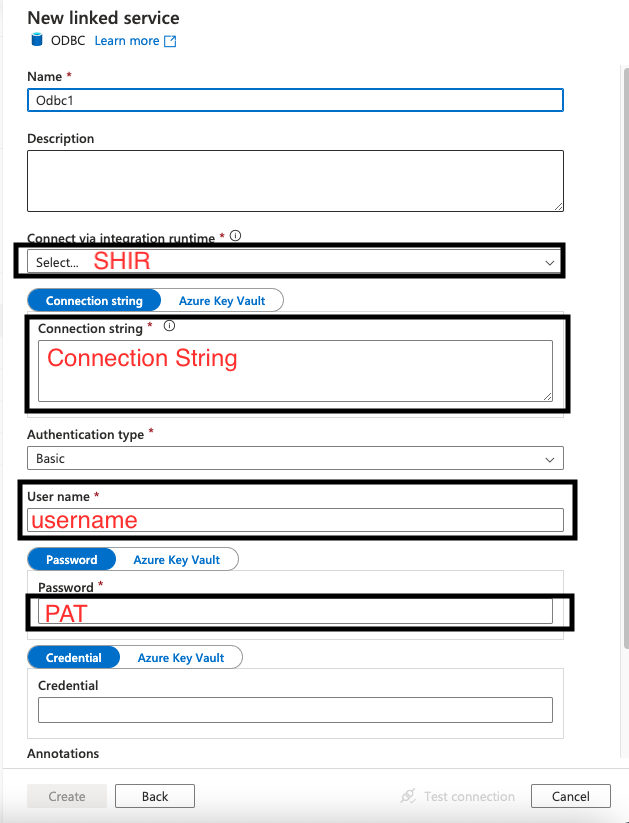
Note: If you don’t specify catalog in connection string, in copy data tool wizard, you won’t be able to browse databases and tables in Unity. Only databases and tables in hive_metastore will be browsable. You can still write sql query (“select * from catalog.database.table”) to query tables in Unity. Alternatively, you can specify a catalog in the connection string by adding “Catalog=XXX”, you can then browse the databases and tables in that catalog in the copy wizard. This additional Catalog setting is necessary if you are using unity catalog as destination data store, so that databases and tables in Unity is browsable when setting up destination.
*Below steps use SQL DB is the example target for Copy Data Tool..
If your target SQL DB is not restricted to only private access, go to 6A, otherwise go to 6B.
6A. Set up a copy activity, using SHIR as integration runtime and ODBC linked service as source and default Azure IR as integration runtime and SQL DB as destination
6B. Add a private endpoint in the SQL DB networking tab in Azure Portal, the private endpoint should be in the same region as the Vnet of Databricks, and connect the private endpoint to the Vnet and subnet of the VM hosting SHIR
From there you have two choices, you can either
7A. Set up a copy activity, using SHIR as integration runtime and ODBC linked service as source and SHIR as integration runtime and SQL DB as destination
Or
7B. Create a new Azure IR in ADF in Managed Vnet, create a Managed Private Endpoint in ADF connecting to the SQL DB ( you will need to approve the Private endpoint in the SQL DB Azure portal). Set up a copy activity, using SHIR as integration runtime and ODBC linked service as source and Managed Vnet Azure IR as integration runtime and SQL DB as destination
Considerations
Multiple ADFs can share the same SHIR (note shared SHIR is not available in Synapse), so if you have multiple consumers that need to connect to the same Databricks instance, you can set up linked IR
Above is two ways to get around the ADF delta connector not being updated for Unity yet. Do you know other ways? Comment to let me know!