The Problem Statement
The lives of the central data teams are hard these days because they typically work with a lot of internal stakeholders with everchanging requirements for the data that they need to provide in ways that are incompatible with the central platform. In other words, they often get requests as such:
–“It’s great you have built this dashboard; now, how about making this blue bluer?”
–“I also need weather data to be added to the data model.”
–“Can I get this report in Excel by email every week?”
I’ve been working with many customers who have a central data team that is busy fulfilling these types of requests on an ad hoc basis in a reactive way day in and day out. This is not fun. Rework is frustrating. Running around fulfilling ad hoc requests without structure and repeatability is tedious. Getting “creative” to fulfil one-off requests creates tech debts and can be dangerous. What is the root cause of it all? The central data team is used as a service provider for their business units. From producing data to changing data models, to reproducing data visualization, to doing the plumbing to connect to the apps/services that internal stakeholders would like to consume the data in, the work these service-providing central data teams are doing is not scalable, nor repeatable.
If you prefer consuming the content in a video format, click on the video link. Otherwise, feel free to read ahead.
The Enterprise Data Serving Framework
How can this be changed? You need an enterprise data serving framework. With a well-designed framework, the central data team can change its role from service provider to data producer and provide a framework and a repeatable pattern that allows its internal customers to consume their data with the minimum friction. They can switch from a reactive to a proactive way of working.
What does an enterprise data serving framework look like? First, the logical design of this serving framework is technology agnostic. In this blog, I will use Databricks features to explain the physical design. Depending on the cloud provider or data platform you are using, you can make the physical design according to the logical pattern.
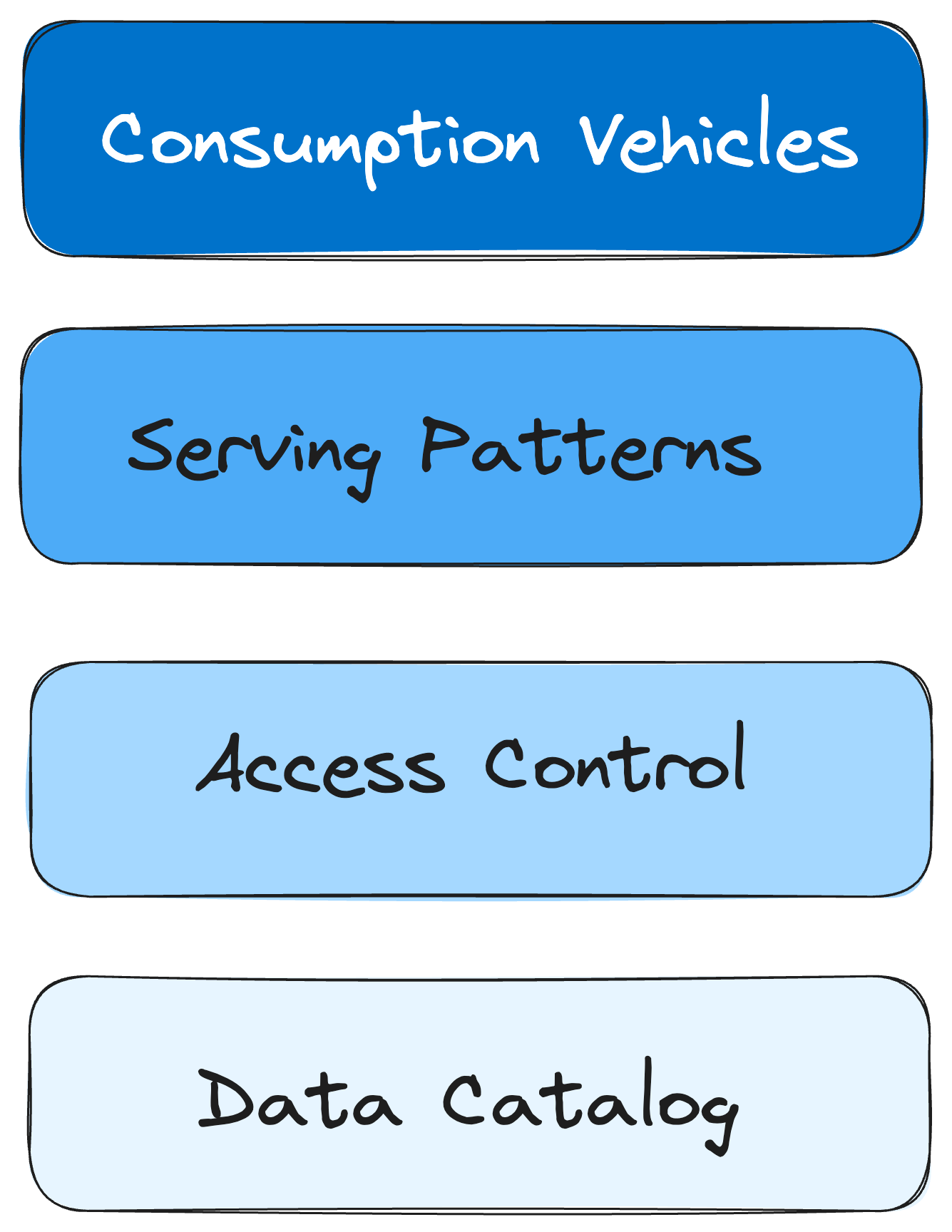
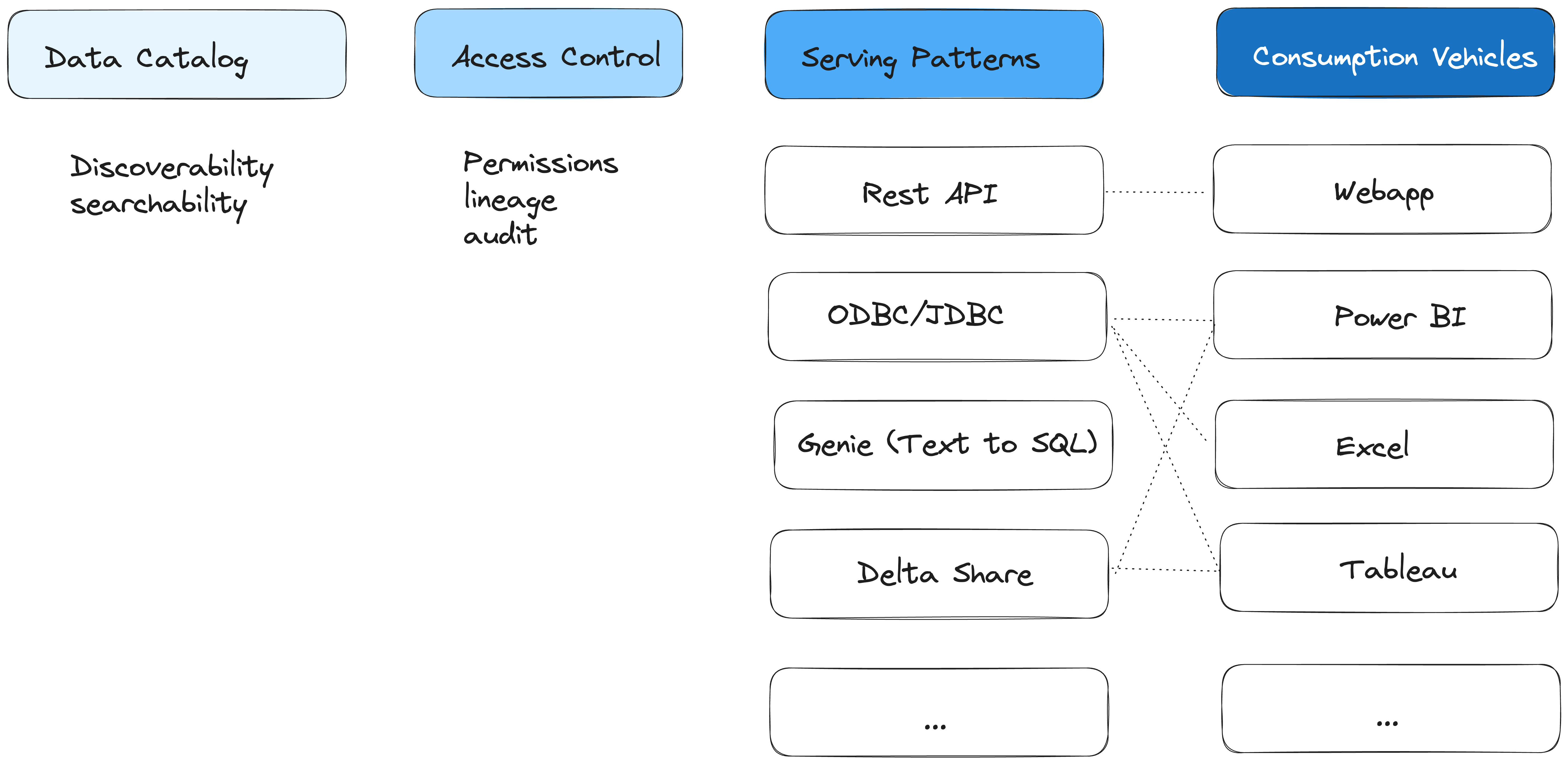
The logical design for the enterprise serving framework has four layers. The consumption vehicle, the serving pattern, the access control and the data catalog. Each layer is interrelated. Key consumption vehicles inform the choices of serving patterns that central data team will provide. All of the serving patterns should be governed by a single consolidated access control mechanism. The subjects of access control are the tables and schemas in the data catalog.
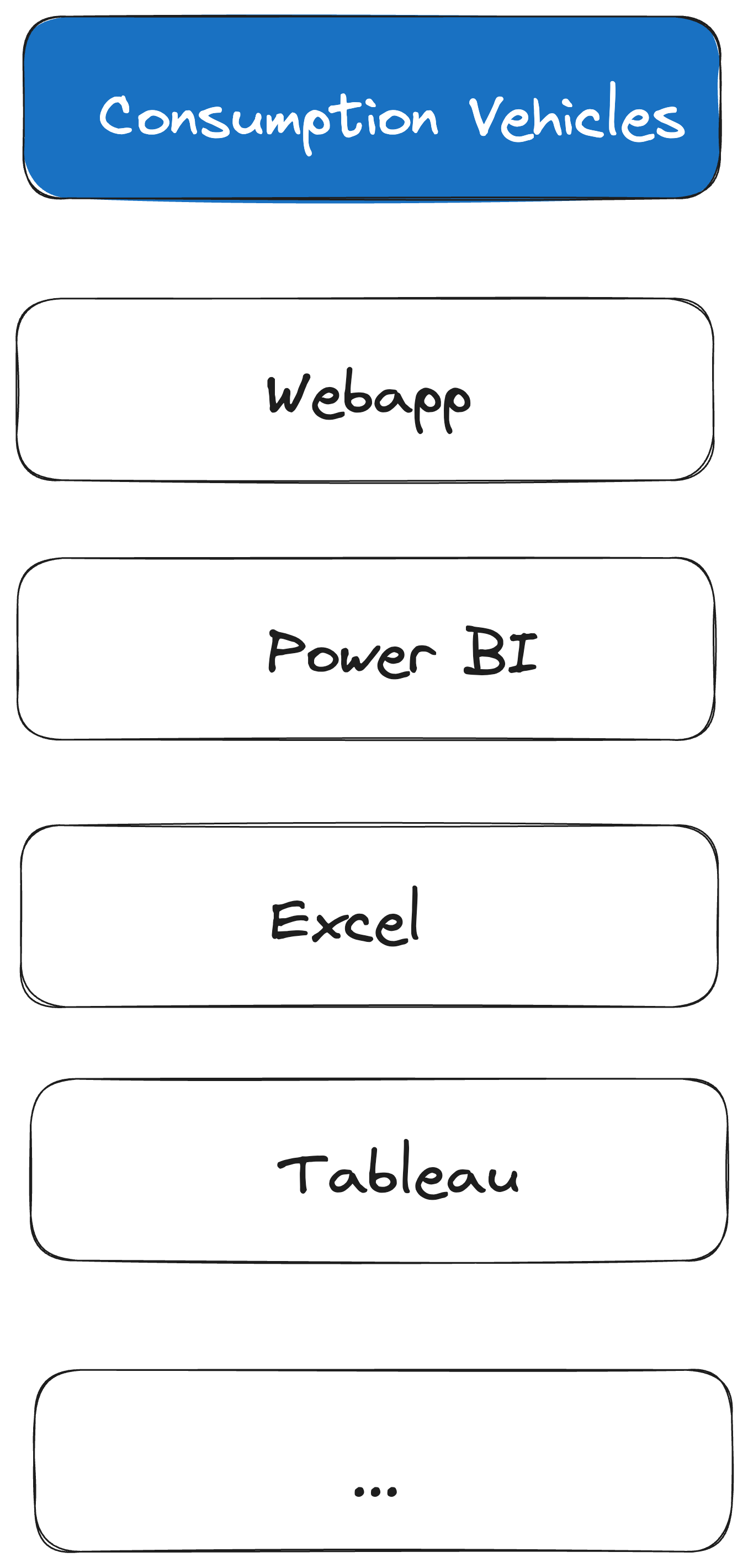
The Consumption Vehicles
Start with mapping what your internal customers are using as consumption vehicles: Power BI, Excel, Tableau, WebApp…You want to use the 80/20 rule and understand what your most important internal (or in some cases external) customers are using as consumption vehicles, so you can design your serving patterns accordingly.
Some consumption vehicles are very common. There are 4 billion Excel users in the world and 30 million monthly active users of Power BI. There is a good chance that some of your internal customers are asking for data to be consumed in either Power BI or Excel. Sometimes, your internal customers spend their lives in SaaS applications, so they would want to consume the data that you provide in applications like Salesforce or Dynamics. Other times, your customer wants to consume the data in some bespoke custom-built applications. It is worth noting that you will likely get consumption vehicles everywhere on the spectrum when you map out what your customers are using, especially if you work in an umbrella company or company that grew via M&A.
It is not necessary to cater for every consumption vehicle request. 1. Some customers are willing to consume data in more than one consumption vehicle. 2. If a particular consumption vehicle requires the central data team to build a new serving pattern that takes tremendous engineering effort, it might be worthwhile to convince/influence the customer to use a different consumption vehicle. 3. Once the enterprise data serving framework is published within the organization, internal customers will gain an understanding of what serving patterns are available and which consumption vehicles are supported. They could be willing to migrate to supported vehicles. This will massively reduce and eventually eliminate the ad hoc effort needed from central data team to build connectivity to bespoke consumption vehicles.
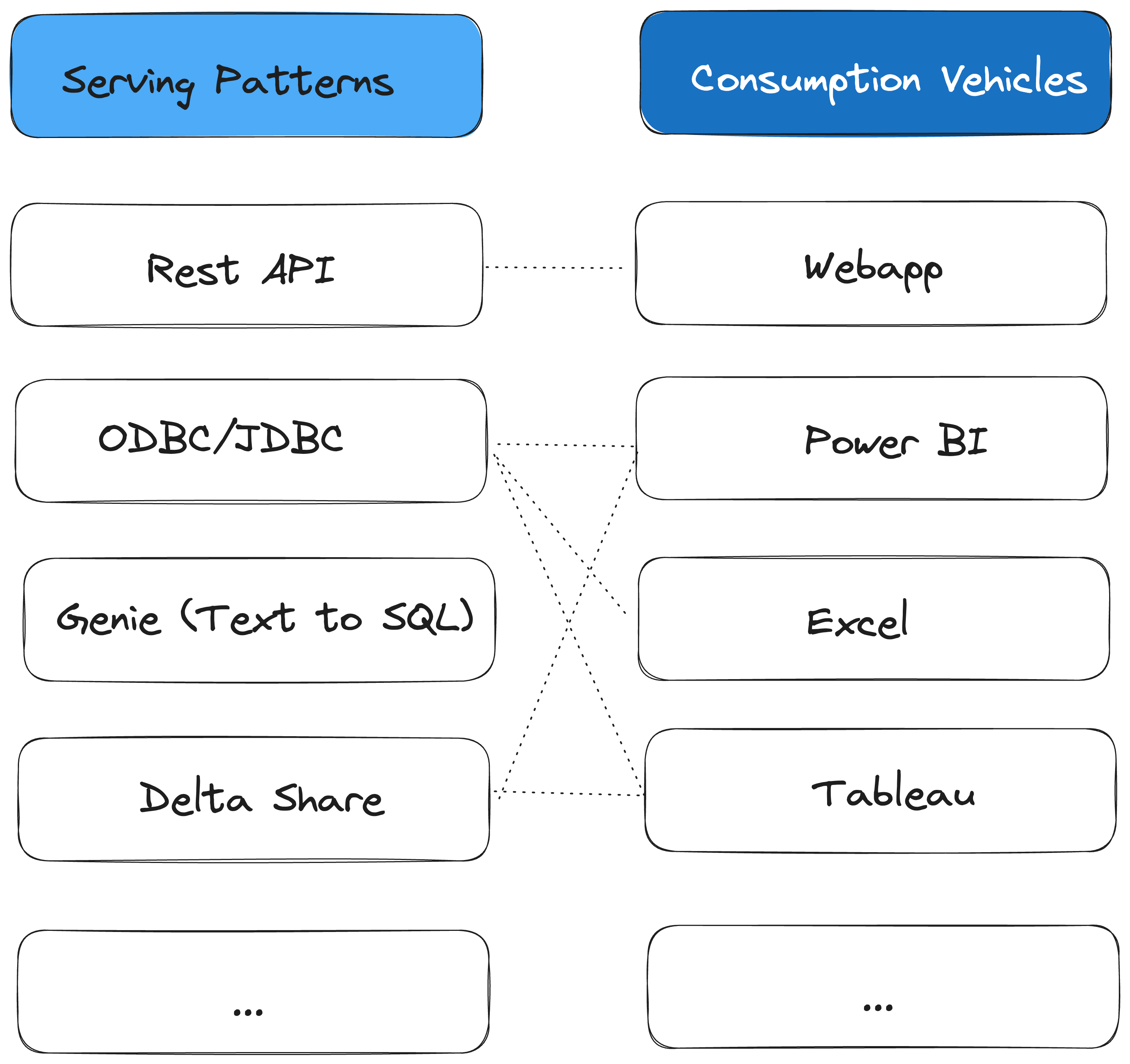
The Serving Patterns
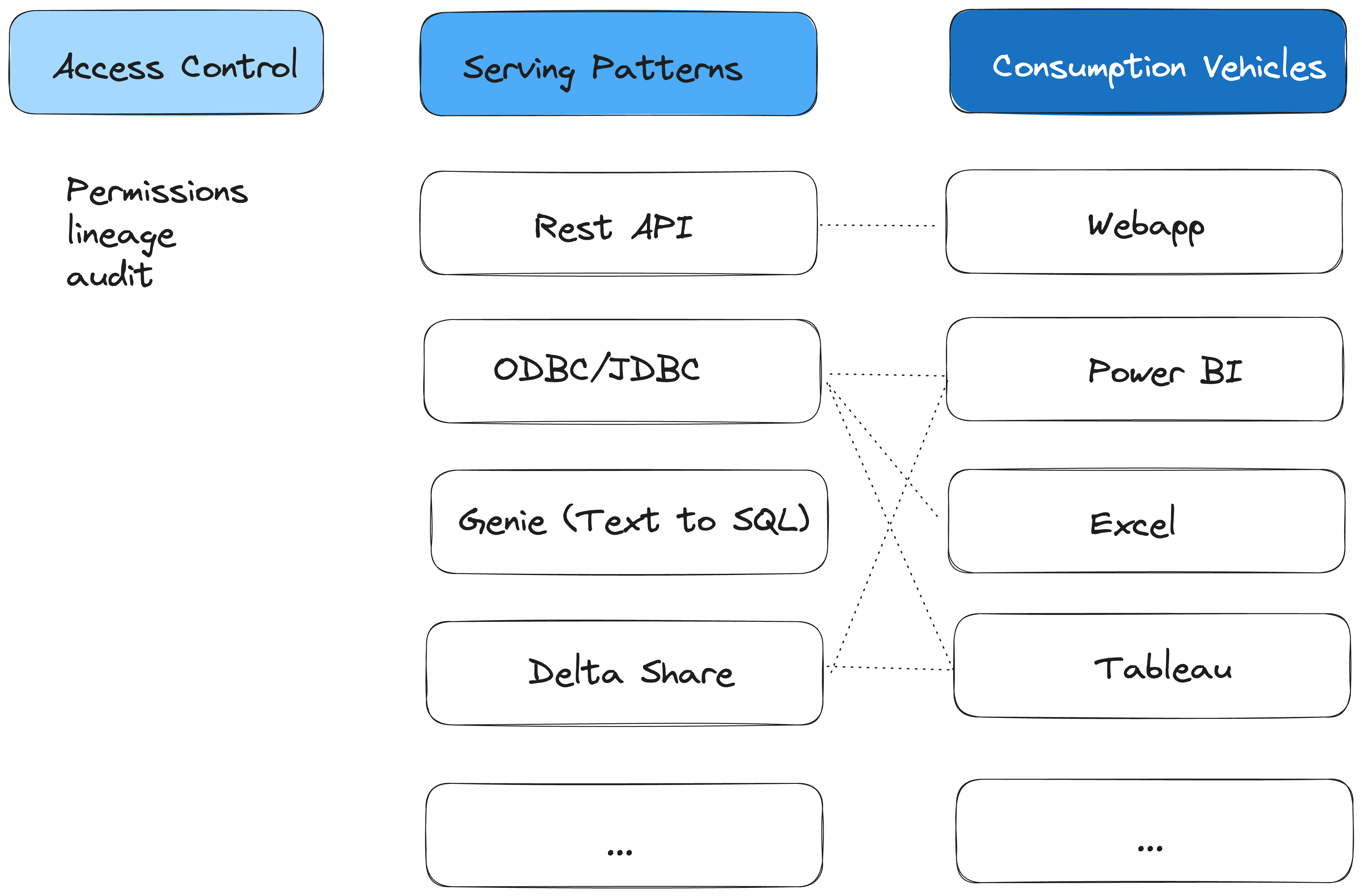
The design of serving patterns is informed by mapped-out consumption vehicles. What your serving patterns are depends on what platform you are using. The design philosophy is to use the minimum amount of serving patterns to meet as many consumption vehicles as possible. For instance, if you have a serving pattern that is an ODBC/JDBC connector, it can be used for consumption vehicles like Power BI, Tableau, Excel and any other services that can connect to ODBC/JDBC. If you have a serving pattern that is Rest API. It can be used for any web app or mobile app. You could have a serving pattern that is Text-to-SQL, which can be used for a chatbot on top of your structured data. In Databricks, all above-mentioned serving patterns can be achieved by DBSQL. When it comes to serving as many consumption vehicles as possible, Delta Share is a good example. Delta Share is an open standard and the recipient of Delta Share does not need to be Databricks, can be anything that supports Delta Share open standard, such as Power BI, Pandas etc.
Supported Serving Patterns and Consumption Vehicles should be well advertised within the organization. Request for supporting additional serving patterns and consumption vehicles should be qualified and managed in a structured and managed manner and separately from data request.
The Access Control
Next is the governance layer. Before Serving Patterns are published to internal customers as self-service features, you want to implement access control here. Not everybody should have access to everything. It’s important that the governance layer is unified, in other words, regardless of Serving Patterns, the access control should be managed in a single mechanism. In Databricks, that mechanism is Unity Catalog. In addition to access control, Unity Catalog gives you auditability and lineage as well, so that you can audit who has access what when and do root cause analysis on anything that did not function at the consumption vehicle layer.
Access control should be implemented in a structured and scalable manner. Data stewards and data owners decide as per each catalogue or each schema, which teams have access to it. These teams should be set up as groups in your identity provider. As people get onboarded to a new team or new organization, they get added to their identity provider groups. Because they’re part of the group, they automatically have access to the data that they should have access to, all the dashboards or the genie rooms, and direct query Power BI datasets.
The Data Catalog
The foundation of the enterprise data serving framework is the data. Data is the subject that all the following layers to govern, serve and consume. Data needs to be discoverable and searchable. Data needs metadata that explains the content of the table/columns so they can be easily understood by self-servicing internal stakeholders. The metadata should include data quality metrics, so that self-serving internal stakeholders have visibility on the completeness, timelyness, and accuracy of the data and can make decisions on whether and how to use the data.
The Operational Model
The enterprise data serving framework needs to give internal stakeholders visibility on below items:
- What data is available?
- The description of the data including data quality metrics
- Sensitivity labels (PII, PHI etc)
- Who has access to the data?
- Permissions
- Who’s the data owner/steward
- What are the serving patterns supported?
- Which consumption vehicles can each serving pattern support
- How to connect/troubleshoot
- What are the consumption vehicles supported?
- Which serving pattern to use based on your consumption vehicle choice?
- How to acquire a license (if any)
- How to connect/troubleshoot
- How do I make a change request to the central data team
- How do you request additional data in the data catalog?
- How do you request access?
- How do you request an additional serving pattern/consumption vehicle?
- What are the SLA for 5.a, 5.b and 5.c separately (if any)
In this setup, the enterprise central data team works in a proactive manner and provides data as a service to the rest of the organization and the above checklist provides the basis for a service catalog for data.